Python HTTP

Python HTTP
NihilPython HTTP
其实Python采集网络数据以及与用户交互的能力或许没有JavaScript强,但是对采集到的数据进行分析,二次加工以及数据库存储的能力就要好很多。随着社会的发展,科学技术的提升,发展的不只有爬虫技术,还有反爬技术和企业对数据保护的重视程度。许多视频的部分案例已经失效,包括O’Reilly的部分老版书籍。反爬技术也是根据爬虫技术衍生而来的,只要我们不断地提高技术,可见即可爬。
Python爬虫思路
1.明确需求(Website)
2.发送请求(Request)
- 请求方式:Get、Post
- 请求URL:URL全称统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL唯一来确定
- 请求头:头部信息如User-Agent、Host、Cookies等信息
- 请求体:请求时额外携带的数据,如表单提交时的表单数据
3.获取数据(Response)
- 响应状态:有多种响应状态,如200代表成果、301跳转、404找不到页面、502服务器错误等
- 响应头:如内容类型、内容长度、服务器信息、设置Cookie等
- 响应体:最主要的部分、包含了请求资源的内容,如网页的HTML、图片的二进制数据等
4.解析数据(Parse)
- 直接处理
- Json解析
- 正则表达式
- BeautifulSoup
- Parsel
- Xpath/CSS
5.存储数据(Database)
- 文本:如纯文本、Json、Xml等
- 关系型数据库:如MySQL、Orcacle、SQL Server等
- 非关系型数据库:如MongoDB、Redis等key-value形式储存
- 二进制文件:如图片、视频、音频等直接保存成特定文件格式
实战(QQ壁纸)
指定URL
import requests
import parsel # 引入第三方库
# 目标网址:
base_url = 'http://www.qqbizhi.com/desk/meinv/'打开网址,看到有二十一张图片,点开来发现其实是另一个网址,因此我们要在基地址抓取到第二级地址,再对图片进行抓取。
UA伪装
UA,即User-Agent,也就是请求头,随便打开一个网址,按下F12
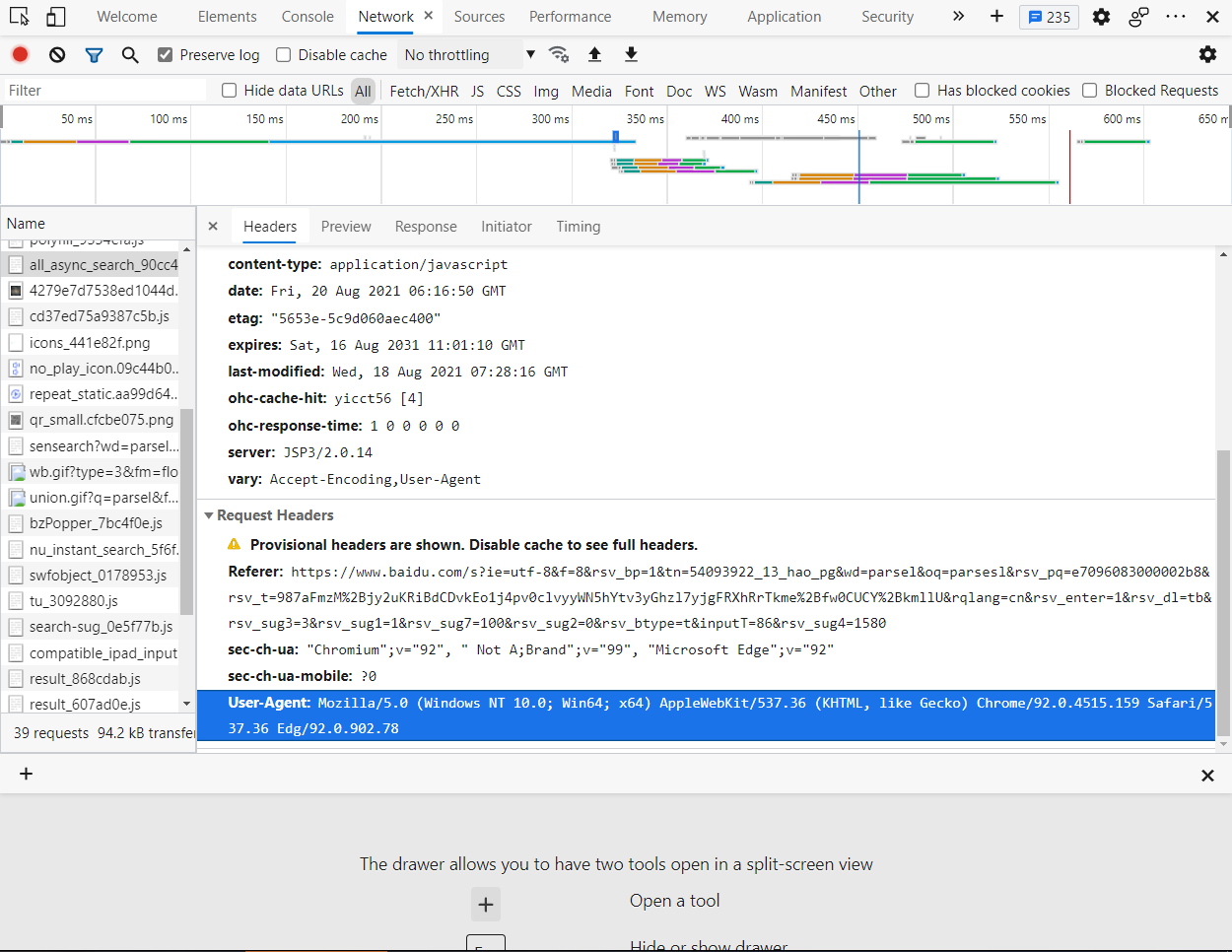
看!蓝色的,即是UA,不配置的话默认是python哦。那该如何配置呢?修改headers中的键值对即可,即加上下面这句话:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) '
'Gecko/20100101 Firefox/91.0'}发起请求(模拟浏览器)
# get返回结果赋值给response
response = requests.get(url=base_url, headers=headers)
# 配置编码方式,使其自适应网站编码类型
response.encoding = response.apparent_encoding
# 获取文本
data = response.text这里注意,后面保存图片为二进制,获取二进制数据格式就要用content
- response.text 返回的是一个 unicode 型的文本数据
- response.content 返回的是 bytes 型的二进制数据
获取相应数据
# parsel解析,获取HTML源码
html_data = parsel.Selector(data)
# xpath对目标定位
data_list = html_data.xpath('//div[@class="imglist"]/figure/a/@href').extract()
# 获取目标赋给一个列表(不止一个目标)
result = ['http://www.qqbizhi.com' + data_url for data_url in data_list]这里涉及一丢丢xpath语法:
//表示跨行定位
[@class=“xxxxxxx”]表示属性class的值为xxxxxxx的标签,也可通过id等其他属性进行定位,但要注意有些属性是动态属性,一般就取id或class。
@href其属性的值就是我们所需,结合基地址赋值,后面进行循环提取
解析数据
# 对每个url进行抓取
for any_list in result:
# 同上,基地址变为相册地址,UA依旧
response_2 = requests.get(url=any_list, headers=headers).text
response_2_data = parsel.Selector(response_2)
img_url = response_2_data.xpath('//div[@class="container"]'
'//div/figure/a/@data-src').extract_first()
if img_url == None:
img_url = response_2_data.xpath('//div[@class="pc-container"]'
'//div/figure/a/@data-src').extract_first()- extract():这个方法返回一个数组,里面是str类型!。
- extract_first():这个方法返回一个string字符串,是其数组里面第一个字符串哦。
进行持久化储存
# 获取二进制图片数据并赋值
img_data = requests.get(url=img_url, headers=headers).content
# 对图片进行命名,截取最后一个/后的数据
file_name = img_url.split('/')[-1]
# 打开本目录下创建好的img文件夹进行写入
# <insert>
with open('img\\' + file_name, mode='wb') as f:
# 打印进度
print('Downloading: ', file_name)
f.write(img_data)每次抓都要新建文件夹是不是太麻烦哦,引入os库(虽然打过包后会被360安全卫士报毒…emm)
# 在<insert>处插入下面代码,当然第一行也不要忘记import os
if not os.path.exists('img'):
os.mkdir('img')os库判断当前文件夹下是否有名为‘img’的文件夹,如果没有就创建。
完善程序
扩大抓取范围
不行,只抓取第一页的二十一张图片已经满足不了我的欲望 (>.<)
那么,现在就来扩大抓取范围!
记得基地址是:
http://www.qqbizhi.com/desk/meinv/我们来点开第二页,你会发现地址变成了:
http://www.qqbizhi.com/desk/meinv/index_2.html点开第三页:
http://www.qqbizhi.com/desk/meinv/index_3.html好的,规律显而易见,我们只需要index_{page}进行for循环即可多页抓取。
for page in range(1, 36):
if page == 1:
base_url = 'http://www.qqbizhi.com/desk/meinv/'
else:
base_url = 'http://www.qqbizhi.com' \
'/desk/meinv/index_{}.html'.format(str(page))将整个程序放在for函数里进行抓取即可实现多页抓取。
现在,我们来让程序打印抓取进度
# 程序开头部分做分割线
print("----------------------------------------------")在for循环里,对每一页进行提醒
print('--------{} page downloading---------'.format(page))异常捕获
在没有网络连接的时候、服务器崩溃的时候、目标标签框架变更的时候等等各种因素都会影响到我们对数据的采集,这时,对部分异常的可控处理就显得尤为重要。
好在requests已经对部分异常给予返回值进行提醒,我们可以根据这些返回值,进行判断处理。
try:
# 主程序
except requests.Timeout as e:
print("出现异常,请查看网络连接或过段时间重试\n")
except requests.URLRequired as e:
print("出现异常,请查看网络连接或过段时间重试\n")
except requests.ConnectionError as e:
print("出现异常,请查看网络连接或过段时间重试\n")
except requests.HTTPError as e:
print("出现异常,请查看网络连接或过段时间重试\n")一些requests库的异常总结
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败,拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
| r.raise_for_status | 如果不是200,产生异常requestsHTTPError |
| requests.URLRequired | URL缺失异常 |
sleep延迟
为了不给目标服务器过大压力、通常每个循环便添加一个sleep延迟(和平相处嘛 😝
爬虫数据解析的方法
- 正则表达式——使用场景:数据量相对较少,或者要提取的类型单一,专门用于从字符串里面提取数据
- css选择器——使用场景:适合在html标签中提取数据
- xpath——使用场景:适合在html标签当中进行数据提取,路径选择器,最早是提取xml文件,因为简单易学,在网页方面的引用比较多
xpath、parsel简介
XPath是一门在HTML、XML文档中查找信息的语言
parsel是一款高性能的python HTML、XML解析器,将字符串转化为selector对象,具有xpath方法,返回结果的列表,能够接受bytes类型的数据和str类型的数据,我们可以可利用xpath,来快速定位元素以及获取节点信息
xpath语法
xpath使用路径表达式来选取xml文档中的节点或者节点集
| 表达式 | 描述 |
|---|---|
| nodename | 选中该元素 |
| / | 从根节点获取,或者是元素之间的过渡 |
| // | 跨节点提取 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
- 选取未知节点
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型节点 |
| /div/* | 选取div元素的所有子元素 |
| //* | 选取文档中的所有元素 |
| //title]@*] | 选取所有带有属性title的元素 |